
JVM(Java Virtual Machine).
JVM (Java Virtual Machine) is an abstract machine. It is a specification that provides runtime environment in which java bytecode can be executed.
JVMs are available for many hardware and software platforms (i.e. JVM is platform dependent).
What is JVM?
Introducing the Java Virtual Machine.
The JVM manages system memory and provides a portable execution environment for Java-based applications.
The Java Virtual Machine is a program whose purpose is to execute other programs.The JVM upset the status quo for its time, and continues to support programming innovation today.
It is,
- A specification where working of Java Virtual Machine is specified. But implementation provider is independent to choose the algorithm. Its implementation has been provided by Oracle and other companies.
- An implementation Its implementation is known as JRE (Java Runtime Environment).
- Runtime Instance Whenever you write java command on the command prompt to run the java class, an instance of JVM is created.
What the JVM is used for.
The JVM has two primary functions: to allow Java programs to run on any device or operating system (known as the “Write once, run anywhere” principle), and to manage and optimize program memory. When Java was released in 1995, all computer programs were written to a specific operating system, and program memory was managed by the software developer. So the JVM was a revelation.
Having a technical definition for the JVM is useful, and there’s also an everyday way that software developers think about it. Let’s break those down,
- Technical definition: The JVM is the specification for a software program that executes code and provides the runtime environment for that code.
- Everyday definition: The JVM is how we run our Java programs. We configure the JVM’s settings and then rely on it to manage program resources during execution.
When developers talk about the JVM, we usually mean the process running on a machine, especially a server, that represents and controls resource usage for a Java app. Contrast this to the JVM specification, which describes the requirements for building a program that performs these tasks.
What it does?
The JVM performs following operation,
- Loads code
- Verifies code
- Executes code
- Provides runtime environment
JVM provides definitions for the,
- Memory area
- Class file format
- Register set
- Garbage-collected heap
- Fatal error reporting etc.
Who develops and and maintains the JVM?
The JVM is widely deployed, heavily used, and maintained by some very bright programmers, both corporate and open source. The OpenJDK project is the offspring of the Sun Microsystems decision to open-source Java. OpenJDK has continued through Oracle’s stewardship of Java, with much of the heavy lifting these days done by Oracle engineers.
Memory management in the JVM.
The most common interaction with a running JVM is to check the memory usage in the heap and stack. The most common adjustment is tuning the JVM’s memory settings.
Garbage collection,
Before Java, all program memory was managed by the programmer. In Java, program memory is managed by the JVM. The JVM manages memory through a process called garbage collection, which continuously identifies and eliminates unused memory in Java programs. Garbage collection happens inside a running JVM.
In the early days, Java came under a lot of criticism for not being as “close to the metal” as C++, and therefore not as fast. The garbage collection process was especially controversial. Since then, a variety of algorithms and approaches have been proposed and used for garbage collection. With consistent development and optimization, garbage collection has vastly improved.
What does ‘close to the metal’ mean?
When programmers say a programming language or platform is “close to the metal,” we mean the developer is able to programmatically (by writing code) manage an operating system’s memory. In theory, programmers can wring more performance out of our programs by stipulating how much is used and when to discard it. In most cases, delegating memory management to a highly refined process like the JVM yields better performance and fewer errors than doing it yourself.
The JVM in three parts.
It could be said there are three aspects to the JVM: specification, implementation and instance. Let’s consider each of these.
1. The JVM specification.
First, the JVM is a software specification. In a somewhat circular fashion, the JVM spec highlights that its implementation details are not defined within the spec, in order to allow for maximum creativity in its realization:
“To implement the Java virtual machine correctly, you need only be able to read the
classfile format and correctly perform the operations specified therein."
J.S. Bach once described creating music similarly:
“All you have to do is touch the right key at the right time.”
So, all the JVM has to do is run Java programs correctly. Sounds simple, might even look simple from outside, but it is a massive undertaking, especially given the power and flexibility of the Java language.
The JVM as a virtual machine,
The JVM is a virtual machine that runs Java class files in a portable way. Being a virtual machine means the JVM is an abstraction of an underlying, actual machine — such as the server that your program is running on. Regardless of what operating system or hardware is actually present, the JVM creates a predictable environment for programs to run within. Unlike a true virtual machine, however, the JVM doesn’t create a virtual operating system. It would be more accurate to describe the JVM as a managed runtime environment, or a process virtual machine.
2. JVM implementations.
Implementing the JVM specification results in an actual software program, which is a JVM implementation. In fact, there are many JVM implementations, both open source and proprietary. OpenJDK’s HotSpot JVM is the reference implementation, and remains one of the most thoroughly tried-and-tested codebases in the world. HotSpot is also the most commonly used JVM.
Almost all licensed JVM’s are created as forks off the OpenJDK and the HotSpot JVM, including Oracle’s licensed JDK. Developers creating a licensed fork off the OpenJDK are often motivated by the desire to add OS-specific performance improvements. Typically, you download and install the JVM as a bundled part of a Java Runtime Environment (JRE).
3. A JVM instance.
After the JVM spec has been implemented and released as a software product, you may download and run it as a program. That downloaded program is an instance (or instantiated version) of the JVM.
Most of the time, when developers talk about “the JVM,” we are referring to a JVM instance running in a software development or production environment. You might say, “Hey Anand, how much memory is the JVM on that server using?” or, “I can’t believe I created a circular call and a stack overflow error crashed my JVM. What a newbie mistake!”
What is a software specification?
A software specification (or spec) is a human-readable design document that describes how a software system should operate. The purpose of a specification is to create a clear description and requirements for engineers to code to.
Loading and executing class files in the JVM,
We’ve talked about the JVM’s role in running Java applications, but how does it perform its function? In order to run Java applications, the JVM depends on the Java class loader and a Java execution engine.
JVM Architecture.
Let’s understand the internal architecture of JVM. It contains classloader, memory area, execution engine etc.

The Java class loader in the JVM,
Everything in Java is a class, and all Java applications are built from classes. An application could consist of one class or thousands. In order to run a Java application, a JVM must load compiled .class files into a context, such as a server, where they can be accessed. A JVM depends on its class loader to perform this function.
The Java class loader is the part of the JVM that loads classes into memory and makes them available for execution. Class loaders use techniques like lazy-loading and caching to make class loading as efficient as it can be. That said, class loading isn’t the epic brain-teaser that (say) portable runtime memory management is, so the techniques are comparatively simple.
Every Java Virtual Machine includes a class loader. The JVM spec describes standard methods for querying and manipulating the class loader at runtime, but JVM implementations are responsible for fulfilling these capabilities. From the developer’s perspective, the underlying class loader mechanisms are typically a black box.
1) Classloader.
Classloader is a subsystem of JVM which is used to load class files. Whenever we run the java program, it is loaded first by the classloader. There are three built-in classloaders in Java.
- Bootstrap ClassLoader: This is the first classloader which is the super class of Extension classloader. It loads the rt.jar file which contains all class files of Java Standard Edition like java.lang package classes, java.net package classes, java.util package classes, java.io package classes, java.sql package classes etc.
- Extension ClassLoader: This is the child classloader of Bootstrap and parent classloader of System classloader. It loades the jar files located inside $JAVA_HOME/jre/lib/ext directory.
- System/Application ClassLoader: This is the child classloader of Extension classloader. It loads the classfiles from classpath. By default, classpath is set to current directory. You can change the classpath using “-cp” or “-classpath” switch. It is also known as Application classloader.
//Let’s see an example to print the classloader name
public class ClassLoaderExample{
public static void main(String[] args){
// Let’s print the classloader name of current class.
//Application/System classloader will load this class
Class c=ClassLoaderExample.class;
System.out.println(c.getClassLoader());
//If we print the classloader name of String, it will print null because it is an
//in-built class which is found in rt.jar, so it is loaded by Bootstrap classloader
System.out.println(String.class.getClassLoader());}}
Output:
sun.misc.Launcher$AppClassLoader@4e0e2f2a
null
These are the internal classloaders provided by Java. If you want to create your own classloader, you need to extend the ClassLoader class.
2) Class(Method) Area.
Class(Method) Area stores per-class structures such as the runtime constant pool, field and method data, the code for methods.
3) Heap.
It is the runtime data area in which objects are allocated.
4) Stack.
Java Stack stores frames. It holds local variables and partial results, and plays a part in method invocation and return.
Each thread has a private JVM stack, created at the same time as thread.
A new frame is created each time a method is invoked. A frame is destroyed when its method invocation completes.
5) Program Counter Register.
PC (program counter) register contains the address of the Java virtual machine instruction currently being executed.
6) Native Method Stack.
It contains all the native methods used in the application.
The execution engine in the JVM,
Once the class loader has done its work of loading classes, the JVM begins executing the code in each class. The execution engine is the JVM component that handles this function. The execution engine is essential to the running JVM. In fact, for all practical purposes, it is the JVM instance.
Executing code involves managing access to system resources. The JVM execution engine stands between the running program — with its demands for file, network and memory resources — and the operating system, which supplies those resources.
How the execution engine manages system resources,
System resources can be divided into two broad categories: memory and everything else.
Recall that the JVM is responsible for disposing of unused memory, and that garbage collection is the mechanism that does that disposal. The JVM is also responsible for allocating and maintaining the referential structure that the developer takes for granted. As an example, the JVM’s execution engine is responsible for taking something like the new keyword in Java, and turning it into an OS-specific request for memory allocation.
Beyond memory, the execution engine manages resources for file system access and network I/O. Since the JVM is interoperable across operating systems, this is no mean task. In addition to each application’s resource needs, the execution engine must be responsive to each OS environment. That is how the JVM is able to handle in-the-wild demands.
7) Execution Engine.
It contains,
- A virtual processor
- Interpreter: Read bytecode stream then execute the instructions.
- Just-In-Time(JIT) compiler: It is used to improve the performance. JIT compiles parts of the byte code that have similar functionality at the same time, and hence reduces the amount of time needed for compilation. Here, the term “compiler” refers to a translator from the instruction set of a Java virtual machine (JVM) to the instruction set of a specific CPU.
8) Java Native Interface.
Java Native Interface (JNI) is a framework which provides an interface to communicate with another application written in another language like C, C++, Assembly etc. Java uses JNI framework to send output to the Console or interact with OS libraries.
JVM evolution: Past, present, future.
In 1995, the JVM introduced two revolutionary concepts that have since become standard fare for modern software development: “Write once, run anywhere” and automatic memory management. Software interoperability was a bold concept at the time, but few developers today would think twice about it. Likewise, whereas our engineering forebears had to manage program memory themselves, my generation grew up with garbage collection.
We could say that James Gosling and Brendan Eich invented modern programming, but thousands of others have refined and built on their ideas over the following decades. Whereas the Java Virtual Machine was originally just for Java, today it has evolved to support many scripting and programming languages, including Scala, Groovy, and Kotlin. Looking forward, it’s hard to see a future where the JVM isn’t a prominent part of the development landscape.
The lean, mean, virtual machine.
An introduction to the basic structure and functionality of the Java Virtual Machine.
Welcome to the first installment of “Under The Hood.” In this column I’d like to explore topics concerning the inner workings of Java. Each month I’ll focus on one area and attempt to demystify it. My aim is to help programmers understand what is actually going on when they compile and run their Java programs. In this installment, I provide an introduction to the basic structure and functionality of the Java Virtual Machine.
What is the Java Virtual Machine? Why is it here?
The Java Virtual Machine, or JVM, is an abstract computer that runs compiled Java programs. The JVM is “virtual” because it is generally implemented in software on top of a “real” hardware platform and operating system. All Java programs are compiled for the JVM. Therefore, the JVM must be implemented on a particular platform before compiled Java programs will run on that platform.
The JVM plays a central role in making Java portable. It provides a layer of abstraction between the compiled Java program and the underlying hardware platform and operating system. The JVM is central to Java’s portability because compiled Java programs run on the JVM, independent of whatever may be underneath a particular JVM implementation.
What makes the JVM lean and mean? The JVM is lean because it is small when implemented in software. It was designed to be small so that it can fit in as many places as possible — places like TV sets, cell phones, and personal computers. The JVM is mean because it of its ambition. “Ubiquity!” is its battle cry. It wants to be everywhere, and its success is indicated by the extent to which programs written in Java will run everywhere.
Java bytecodes
Java programs are compiled into a form called Java bytecodes. The JVM executes Java bytecodes, so Java bytecodes can be thought of as the machine language of the JVM. The Java compiler reads Java language source (.java) files, translates the source into Java bytecodes, and places the bytecodes into class (.class) files. The compiler generates one class file per class in the source.
To the JVM, a stream of bytecodes is a sequence of instructions. Each instruction consists of a one-byte opcode and zero or more operands. The opcode tells the JVM what action to take. If the JVM requires more information to perform the action than just the opcode, the required information immediately follows the opcode as operands.
A mnemonic is defined for each bytecode instruction. The mnemonics can be thought of as an assembly language for the JVM. For example, there is an instruction that will cause the JVM to push a zero onto the stack. The mnemonic for this instruction is iconst_0, and its bytecode value is 60 hex. This instruction takes no operands. Another instruction causes program execution to unconditionally jump forward or backward in memory. This instruction requires one operand, a 16-bit signed offset from the current memory location. By adding the offset to the current memory location, the JVM can determine the memory location to jump to. The mnemonic for this instruction is goto, and its bytecode value is a7 hex.
Virtual parts
The “virtual hardware” of the Java Virtual Machine can be divided into four basic parts: the registers, the stack, the garbage-collected heap, and the method area. These parts are abstract, just like the machine they compose, but they must exist in some form in every JVM implementation.
The size of an address in the JVM is 32 bits.The JVM can, therefore, address up to 4 gigabytes (2 to the power of 32) of memory, with each memory location containing one byte. Each register in the JVM stores one 32-bit address. The stack, the garbage-collected heap, and the method area reside somewhere within the 4 gigabytes of addressable memory. The exact location of these memory areas is a decision of the implementor of each particular JVM.
A word in the Java Virtual Machine is 32 bits. The JVM has a small number of primitive data types: byte (8 bits), short (16 bits), int (32 bits), long (64 bits), float (32 bits), double (64 bits), and char (16 bits). With the exception of char, which is an unsigned Unicode character, all the numeric types are signed. These types conveniently map to the types available to the Java programmer. One other primitive type is the object handle, which is a 32-bit address that refers to an object on the heap.
The method area, because it contains bytecodes, is aligned on byte boundaries. The stack and garbage-collected heap are aligned on word (32-bit) boundaries.
The proud, the few, the registers
The JVM has a program counter and three registers that manage the stack. It has few registers because the bytecode instructions of the JVM operate primarily on the stack. This stack-oriented design helps keep the JVM’s instruction set and implementation small.
The JVM uses the program counter, or pc register, to keep track of where in memory it should be executing instructions. The other three registers — optop register, frame register, and vars register — point to various parts of the stack frame of the currently executing method. The stack frame of an executing method holds the state (local variables, intermediate results of calculations, etc.) for a particular invocation of the method.
The method area and the program counter
The method area is where the bytecodes reside. The program counter always points to (contains the address of) some byte in the method area. The program counter is used to keep track of the thread of execution. After a bytecode instruction has been executed, the program counter will contain the address of the next instruction to execute. After execution of an instruction, the JVM sets the program counter to the address of the instruction that immediately follows the previous one, unless the previous one specifically demanded a jump.
The Java stack and related registers
The Java stack is used to store parameters for and results of bytecode instructions, to pass parameters to and return values from methods, and to keep the state of each method invocation. The state of a method invocation is called its stack frame. The vars, frame, and optop registers point to different parts of the current stack frame.
There are three sections in a Java stack frame: the local variables, the execution environment, and the operand stack. The local variables section contains all the local variables being used by the current method invocation. It is pointed to by the vars register. The execution environment section is used to maintain the operations of the stack itself. It is pointed to by the frame register. The operand stack is used as a work space by bytecode instructions. It is here that the parameters for bytecode instructions are placed, and results of bytecode instructions are found. The top of the operand stack is pointed to by the optop register.
The execution environment is usually sandwiched between the local variables and the operand stack. The operand stack of the currently executing method is always the topmost stack section, and the optop register therefore always points to the top of the entire Java stack.
The garbage-collected heap
The heap is where the objects of a Java program live. Any time you allocate memory with the new operator, that memory comes from the heap. The Java language doesn’t allow you to free allocated memory directly. Instead, the runtime environment keeps track of the references to each object on the heap, and automatically frees the memory occupied by objects that are no longer referenced — a process called garbage collection.
Eternal math: a JVM simulation
The applet below simulates a JVM executing a few bytecode instructions. The instructions in the simulation were generated by the javac compiler given the following java code:
class Act {
public static void doMathForever() {
int i = 0;
while (true) {
i += 1;
i *= 2;
}
}
}The instructions in the simulation represent the body of the doMathForever() method. These instructions were chosen because they are a short sequence of bytecodes that do something mildly interesting on the stack. This simulation stars the registers, the stack, and the method area. The heap is not involved in this bytecode sequence, so it is not shown as part of the applet’s user interface. All numbers in the simulation are shown in hex.
As our story opens, the program counter (pc register) is pointing to an iconst_0 instruction. The iconst_0 instruction is in the method area, where bytecodes like to hang out.
When you press the Step button, the JVM will execute the single instruction that is being pointed to by the program counter. So, the first time you press the Step button, the iconst_0 instruction, which pushes a zero onto the stack, will be executed. After this instruction has executed,the program counter will be pointing to the next instruction to execute.Subsequent presses of the Step button will execute subsequent instructions and the program counter will lead the way. Pressing the Reset button will cause the simulation to start over at the beginning.
The value of each register is shown two ways. The contents of each register, a 32-bit address, is shown in hex across the top of the simulation. Additionally, I put a small pointer to the address contained in each register next to the address in either the stack or the method area. The address contained by the program counter, for example, has a pc> next to it in the method area.
The Java stack is word-based. Each time something is pushed onto the Java stack, it goes on as a word (although longs and doubles actually go on as two words). In the simulation, the Java stack is shown as an upside-down tower of words. It is shown growing down the panel (up in memory addresses) as words are pushed onto it. The stack recedes back up the panel as words are popped from it. In this implementation of the JVM, the optop register always points to the next available slot on the Java stack.
All three sections of the stack frame for the currently executing method — the local variables, the execution environment, and the operand stack — are shown in the simulation. Only the local variables and operand stack take part in this simulation, though. The execution environment isn’t involved in this particular bytecode sequence, so it is shown filled with zeros.
The local variables section of the Java stack is treated as an array of words starting at the location pointed to by the vars register. Bytecodes that deal with local variables generally include an array index, which is an offset from the vars register. The address of the nth local variable is (vars + (n * 4)). You must multiply n by 4, because each word is 4 bytes long.
The doMathForever() method has only one local variable, i. It is therefore at array position zero and is pointed to directly by the vars register. For example, the iinc instruction takes two byte-sized operands, a local variable index and an amount. In the simulation, “iinc 0 1” increments by one the integer at local variable array position zero. This instruction implements the “i += 1;” statement from doMathForever().
Thread behavior in the JVM.
The JVM does what it wants to do, so how can you predict the order of thread execution?
Threading refers to the practice of executing programming processes concurrently to improve application performance. While it’s not that common to work with threads directly in business applications, they’re used all the time in Java frameworks.
As an example, frameworks that process a large volume of information, like Spring Batch, use threads to manage data. Manipulating threads or CPU processes concurrently improves performance, resulting in faster, more efficient programs.
Find your first thread: Java’s main() method,
Even if you’ve never worked directly with Java threads, you’ve worked indirectly with them because Java’s main() method contains a main Thread. Anytime you’ve executed the main() method, you've also executed the main Thread.
Studying the Thread class is very helpful for understanding how threading works in Java programs. We can access the thread that is being executed by invoking the currentThread().getName() method, as shown here,
public class MainThread { public static void main(String... mainThread) {
System.out.println(Thread.currentThread().getName());
}}
This code will print “main,” identifying the thread currently being executed. Knowing how to identify the thread being executed is the first step to absorbing thread concepts.
The Java thread lifecycle,
When working with threads, it’s critical to be aware of thread state. The Java thread lifecycle consists of six thread states,
- New: A new
Thread()has been instantiated. - Runnable: The
Thread'sstart()method has been invoked. - Running: The
start()method has been invoked and the thread is running. - Suspended: The thread is temporarily suspended, and can be resumed by another thread.
- Blocked: The thread is waiting for an opportunity to run. This happens when one thread has already invoked the
synchronized()method and the next thread must wait until it's finished. - Terminated: The thread’s execution is complete.
There’s more to explore and understand about thread states, but the information in Figure 1 is enough for you to solve this Java challenge.
Concurrent processing: Extending a Thread class,
At its simplest, concurrent processing is done by extending a Thread class, as shown below.
public class InheritingThread extends Thread { InheritingThread(String threadName) {
super(threadName);
} public static void main(String... inheriting) {
System.out.println(Thread.currentThread().getName() + " is running"); new InheritingThread("inheritingThread").start();
} @Override
public void run() {
System.out.println(Thread.currentThread().getName() + " is running");
}
}
Here we’re running two threads: the MainThread and the InheritingThread. When we invoke the start() method with the new inheritingThread(), the logic in the run() method is executed.
We also pass the name of the second thread in the Thread class constructor, so the output will be,
main is running.
inheritingThread is running.The Runnable interface,
Rather than using inheritance, you could implement the Runnable interface. Passing Runnable inside a Thread constructor results in less coupling and more flexibility. After passing Runnable, we can invoke the start() method exactly like we did in the previous example,
public class RunnableThread implements Runnable { public static void main(String... runnableThread) {
System.out.println(Thread.currentThread().getName()); new Thread(new RunnableThread()).start();
} @Override
public void run() {
System.out.println(Thread.currentThread().getName());
}}
Non-daemon vs daemon threads,
In terms of execution, there are two types of threads,
- Non-daemon threads are executed until the end. The main thread is a good example of a non-daemon thread. Code in
main()will be always be executed until the end, unless aSystem.exit()forces the program to complete. - A daemon thread is the opposite, basically a process that is not required to be executed until the end.
Remember the rule: If an enclosing non-daemon thread ends before a daemon thread, the daemon thread won’t be executed until the end.
To better understand the relationship of daemon and non-daemon threads, study this example,
import java.util.stream.IntStream;public class NonDaemonAndDaemonThread { public static void main(String... nonDaemonAndDaemon) throws InterruptedException {
System.out.println("Starting the execution in the Thread " + Thread.currentThread().getName()); Thread daemonThread = new Thread(() -> IntStream.rangeClosed(1, 100000)
.forEach(System.out::println)); daemonThread.setDaemon(true);
daemonThread.start(); Thread.sleep(10); System.out.println("End of the execution in the Thread " +
Thread.currentThread().getName());
}}
In this example I’ve used a daemon thread to declare a range from 1 to 100,000, iterate all of them, and then print. But remember, a daemon thread won’t complete execution if the non-daemon’s main thread finishes first.
The output will proceed as follows:
- Start of execution in the main thread.
- Print numbers from 1 to possibly 100,000.
- End of execution in the main thread, very likely before iteration to 100,000 completes.
The final output will depend on your JVM implementation.
And that brings me to my next point: threads are unpredictable.
Thread priority and the JVM,
It’s possible to prioritize thread execution with the setPriority method, but how it's handled depends on the JVM implementation. Linux, MacOS, and Windows all have different JVM implementations, and each will handle thread priority according to its own defaults.
The thread priority you set does influence the order of thread invocation, however. The three constants declared in the Thread class are,
/**
* The minimum priority that a thread can have.
*/
public static final int MIN_PRIORITY = 1; /**
* The default priority that is assigned to a thread.
*/
public static final int NORM_PRIORITY = 5; /**
* The maximum priority that a thread can have.
*/
public static final int MAX_PRIORITY = 10;
Try running some tests on the following code to see what execution priority you end up with,
public class ThreadPriority { public static void main(String... threadPriority) {
Thread moeThread = new Thread(() -> System.out.println("Moe"));
Thread barneyThread = new Thread(() -> System.out.println("Barney"));
Thread homerThread = new Thread(() -> System.out.println("Homer")); moeThread.setPriority(Thread.MAX_PRIORITY);
barneyThread.setPriority(Thread.NORM_PRIORITY);
homerThread.setPriority(Thread.MIN_PRIORITY); homerThread.start();
barneyThread.start();
moeThread.start();
}}
Even if we set moeThread as MAX_PRIORITY, we cannot count on this thread being executed first. Instead, the order of execution will be random.
Constants vs enums,
The Thread class was introduced with Java 1.0. At that time, priorities were set using constants, not enums. There's a problem with using constants, however: if we pass a priority number that is not in the range of 1 to 10, the setPriority() method will throw an IllegalArgumentException. Today, we can use enums to get around this issue. Using enums makes it impossible to pass an illegal argument, which both simplifies the code and gives us more control over its execution.
Common mistakes with Java threads,
- Invoking the
run()method to try to start a new thread. - Trying to start a thread twice (this will cause an
IllegalThreadStateException). - Allowing multiple processes to change the state of an object when it shouldn’t change.
- Writing program logic that relies on thread priority (you can’t predict it).
- Relying on the order of thread execution — even if we start a thread first, there is no guarantee it will be executed first.
What to remember about Java threads,
- Invoke the
start()method to start aThread. - It’s possible to extend the
Threadclass directly in order to use threads. - It’s possible to implement a thread action inside a
Runnableinterface. - Thread priority depends on the JVM implementation.
- Thread behavior will always depend on the JVM implementation.
- A daemon thread won’t complete if an enclosing non-daemon thread ends first.
Method overloading in the JVM.
Learn how and why Java developers use method overloading, then test your learning against the Java virtual machine itself.
What is method overloading?
Method overloading is a programming technique that allows developers to use the same method name multiple times in the same class, but with different parameters. In this case, we say that the method is overloaded. Listing 1 shows a single method whose parameters differ in number, type, and order.
Listing 1. Three types of method overloading
Number of parameters:
public class Calculator {
void calculate(int number1, int number2) { }
void calculate(int number1, int number2, int number3) { }
}Type of parameters:
public class Calculator {
void calculate(int number1, int number2) { }
void calculate(double number1, double number2) { }
}Order of parameters:
public class Calculator {
void calculate(double number1, int number2) { }
void calculate(int number1, double number2) { }
}
Method overloading and primitive types
In Listing 1, you see the primitive types int and double. We’ll work more with these and other types, so take a minute to review the primitive types in Java.
Table 1. Primitive types in Java

Why should I use method overloading?
Overloading makes your code cleaner and easier to read, and it may also help you avoid bugs in your programs.
In contrast to Listing 1, imagine a program where you had multiple calculate() methods with names like calculate1, calculate2, calculate3 . . . not good, right? Overloading the calculate() method lets you use the same method name while only changing what needs to change: the parameters. It's also very easy to find overloaded methods because they are grouped together in your code.
What overloading isn’t
Be aware that changing a variable’s name is not overloading. The following code won’t compile:
public class Calculator {
void calculate(int firstNumber, int secondNumber){}void calculate(int secondNumber, int thirdNumber){}}
You also can’t overload a method by changing the return type in the method signature. The following code won’t compile, either:
public class Calculator {
double calculate(int number1, int number2){return 0.0;}
long calculate(int number1, int number2){return 0;}
}Constructor overloading
You can overload a constructor the same way you would a method:
public class Calculator {
private int number1;
private int number2; public Calculator(int number1) {this.number1 = number1;}
public Calculator(int number1, int number2) {
this.number1 = number1;
this.number2 = number2;
}}
How the JVM compiles overloaded methods
In order to understand what happened in Listing 2, you need to know some things about how the JVM compiles overloaded methods.
First of all, the JVM is intelligently lazy: it will always exert the least possible effort to execute a method. Thus, when you are thinking about how the JVM handles overloading, keep in mind three important compiler techniques:
- Widening
- Boxing (autoboxing and unboxing)
- Varargs
If you’ve never encountered these three techniques, a few examples should help make them clear. Note that the JVM executes them in the order given.
Here is an example of widening:
int primitiveIntNumber = 5;
double primitiveDoubleNumber = primitiveIntNumber ;This is the order of the primitive types when widened:
Here is an example of autoboxing:
int primitiveIntNumber = 7;
Integer wrapperIntegerNumber = primitiveIntNumber;Note what happens behind the scenes when this code is compiled:
Integer wrapperIntegerNumber = Integer.valueOf(primitiveIntNumber);And here is an example of unboxing:
Integer wrapperIntegerNumber = 7;
int primitiveIntNumber= wrapperIntegerNumber;Here is what happens behind the scenes when this code is compiled:
int primitiveIntNumber = wrapperIntegerNumber.intValue();And here is an example of varargs; note that varargs is always the last to be executed:
execute(int… numbers){}What is varargs?
Used for variable arguments, varargs is basically an array of values specified by three dots (…) We can pass however many int numbers we want to this method.
For example:
execute(1,3,4,6,7,8,8,6,4,6,88...); // We could continue…Varargs is very handy because the values can be passed directly to the method. If we were using arrays, we would have to instantiate the array with the values.
Common mistakes with overloading
By now you’ve probably figured out that things can get tricky with method overloading, so let’s consider a few of the challenges you will likely encounter.
Autoboxing with wrappers
Java is a strongly typed programming language, and when we use autoboxing with wrappers there are some things we have to keep in mind. For one thing, the following code won’t compile:
int primitiveIntNumber = 7;
Double wrapperNumber = primitiveIntNumber;Autoboxing will only work with the double type because what happens when you compile this code is the same as the following:
Double number = Double.valueOf(primitiveIntNumber);The above code will compile. The first int type will be widened to double and then it will be boxed to Double. But when autoboxing, there is no type widening and the constructor from Double.valueOf will receive a double, not an int. In this case, autoboxing would only work if we applied a cast, like so:
Double wrapperNumber = (double) primitiveIntNumber;Remember that Integer cannot be Long and Float cannot be Double. There is no inheritance. Each of these types--Integer, Long, Float, and Double--is a Number and an Object.
When in doubt, just remember that wrapper numbers can be widened to Number or Object. (There is a lot more to explore about wrappers but I will leave it for another post.)
Hard-coded number types in the JVM
When we don’t specify a type to a number, the JVM will do it for us. If we use the number 1 directly in the code, the JVM will create it as an int. If you try to pass 1 directly to a method that is receiving a short, it won’t compile.
For example:
class Calculator {
public static void main(String… args) {
// This method invocation will not compile
// Yes, 1 could be char, short, byte but the JVM creates it as an int
calculate(1);
} void calculate(short number) {}
}
The same rule will be applied when using the number 1.0; although it could be a float, the JVM will treat this number as a double:
class Calculator {
public static void main(String… args) {
// This method invocation will not compile
// Yes, 1 could be float but the JVM creates it as double
calculate(1.0);
} void calculate(float number) {}
}
Another common mistake is to think that the Double or any other wrapper type would be better suited to the method that is receiving a double. In fact, it takes less effort for the JVM to widen the Double wrapper to an Object instead of unboxing it to a double primitive type.
To sum up, when used directly in Java code, 1 will be int and 1.0 will be double. Widening is the laziest path to execution, boxing or unboxing comes next, and the last operation will always be varargs.
As a curious fact, did you know that the char type accepts numbers?
char anyChar = 127; // Yes, this is strange but it compilesWhat to remember about overloading
Overloading is a very powerful technique for scenarios where you need the same method name with different parameters. It’s a useful technique because having the right name in your code makes a big difference for readability. Rather than duplicate the method and add clutter to your code, you may simply overload it. Doing this keeps your code clean and easy to read, and it reduces the risk that duplicate methods will break some part of the system.
What to keep in mind: When overloading a method the JVM will make the least effort possible; this is the order of the laziest path to execution:
- First is widening
- Second is boxing
- Third is Varargs
What to watch out for: Tricky situations will arise from declaring a number directly: 1 will be int and 1.0 will be double.
Also remember that you can declare these types explicitly using the syntax of 1F or 1f for a float or 1D or 1d for a double.
That concludes our first Java Challenger, introducing the JVM’s role in method overloading. It is important to realize that the JVM is inherently lazy, and will always follow the laziest path to execution.
Bytecode basics.
A first look at the bytecodes of the Java virtual machine.
Welcome to another installment of “Under The Hood.” This column gives Java developers a glimpse of what is going on beneath their running Java programs. This month’s article takes an initial look at the bytecode instruction set of the Java virtual machine (JVM). The article covers primitive types operated upon by bytecodes, bytecodes that convert between types, and bytecodes that operate on the stack. Subsequent articles will discuss other members of the bytecode family.
The bytecode format,
Bytecodes are the machine language of the Java virtual machine. When a JVM loads a class file, it gets one stream of bytecodes for each method in the class. The bytecodes streams are stored in the method area of the JVM. The bytecodes for a method are executed when that method is invoked during the course of running the program. They can be executed by intepretation, just-in-time compiling, or any other technique that was chosen by the designer of a particular JVM.
A method’s bytecode stream is a sequence of instructions for the Java virtual machine. Each instruction consists of a one-byte opcode followed by zero or more operands. The opcode indicates the action to take. If more information is required before the JVM can take the action, that information is encoded into one or more operands that immediately follow the opcode.
Each type of opcode has a mnemonic. In the typical assembly language style, streams of Java bytecodes can be represented by their mnemonics followed by any operand values. For example, the following stream of bytecodes can be disassembled into mnemonics:
// Bytecode stream: 03 3b 84 00 01 1a 05 68 3b a7 ff f9
// Disassembly:
iconst_0 // 03
istore_0 // 3b
iinc 0, 1 // 84 00 01
iload_0 // 1a
iconst_2 // 05
imul // 68
istore_0 // 3b
goto -7 // a7 ff f9The bytecode instruction set was designed to be compact. All instructions, except two that deal with table jumping, are aligned on byte boundaries. The total number of opcodes is small enough so that opcodes occupy only one byte. This helps minimize the size of class files that may be traveling across networks before being loaded by a JVM. It also helps keep the size of the JVM implementation small.
All computation in the JVM centers on the stack. Because the JVM has no registers for storing abitrary values, everything must be pushed onto the stack before it can be used in a calculation. Bytecode instructions therefore operate primarily on the stack. For example, in the above bytecode sequence a local variable is multiplied by two by first pushing the local variable onto the stack with the iload_0 instruction, then pushing two onto the stack with iconst_2. After both integers have been pushed onto the stack, the imul instruction effectively pops the two integers off the stack, multiplies them, and pushes the result back onto the stack. The result is popped off the top of the stack and stored back to the local variable by the istore_0 instruction. The JVM was designed as a stack-based machine rather than a register-based machine to facilitate efficient implementation on register-poor architectures such as the Intel 486.
Primitive types
The JVM supports seven primitive data types. Java programmers can declare and use variables of these data types, and Java bytecodes operate upon these data types. The seven primitive types are listed in the following table:
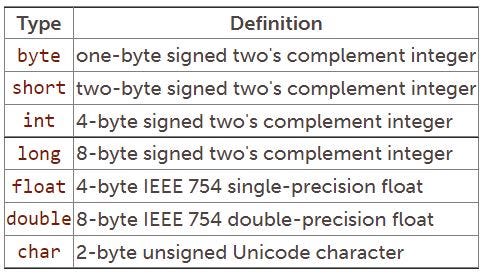
The primitive types appear as operands in bytecode streams. All primitive types that occupy more than 1 byte are stored in big-endian order in the bytecode stream, which means higher-order bytes precede lower-order bytes. For example, to push the constant value 256 (hex 0100) onto the stack, you would use the sipush opcode followed by a short operand. The short appears in the bytecode stream, shown below, as "01 00" because the JVM is big-endian. If the JVM were little-endian, the short would appear as "00 01".
// Bytecode stream: 17 01 00
// Dissassembly:
sipush 256; // 17 01 00Java opcodes generally indicate the type of their operands. This allows operands to just be themselves, with no need to identify their type to the JVM. For example, instead of having one opcode that pushes a local variable onto the stack, the JVM has several. Opcodes iload, lload, fload, and dload push local variables of type int, long, float, and double, respectively, onto the stack.
Pushing constants onto the stack
Many opcodes push constants onto the stack. Opcodes indicate the constant value to push in three different ways. The constant value is either implicit in the opcode itself, follows the opcode in the bytecode stream as an operand, or is taken from the constant pool.
Some opcodes by themselves indicate a type and constant value to push. For example, the iconst_1 opcode tells the JVM to push integer value one. Such bytecodes are defined for some commonly pushed numbers of various types. These instructions occupy only 1 byte in the bytecode stream. They increase the efficiency of bytecode execution and reduce the size of bytecode streams. The opcodes that push ints and floats are shown in the following table:

The opcodes shown in the previous table push ints and floats, which are 32-bit values. Each slot on the Java stack is 32 bits wide. Therefore each time an int or float is pushed onto the stack, it occupies one slot.
The opcodes shown in the next table push longs and doubles. Long and double values occupy 64 bits. Each time a long or double is pushed onto the stack, its value occupies two slots on the stack. Opcodes that indicate a specific long or double value to push are shown in the following table:
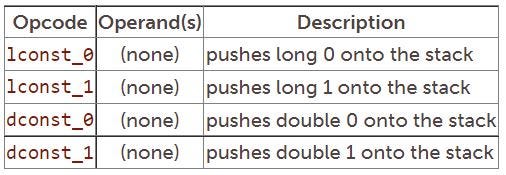
One other opcode pushes an implicit constant value onto the stack. The aconst_null opcode, shown in the following table, pushes a null object reference onto the stack. The format of an object reference depends upon the JVM implementation. An object reference will somehow refer to a Java object on the garbage-collected heap. A null object reference indicates an object reference variable does not currently refer to any valid object. The aconst_null opcode is used in the process of assigning null to an object reference variable.

Two opcodes indicate the constant to push with an operand that immediately follows the opcode. These opcodes, shown in the following table, are used to push integer constants that are within the valid range for byte or short types. The byte or short that follows the opcode is expanded to an int before it is pushed onto the stack, because every slot on the Java stack is 32 bits wide. Operations on bytes and shorts that have been pushed onto the stack are actually done on their int equivalents.

Three opcodes push constants from the constant pool. All constants associated with a class, such as final variables values, are stored in the class’s constant pool. Opcodes that push constants from the constant pool have operands that indicate which constant to push by specifying a constant pool index. The Java virtual machine will look up the constant given the index, determine the constant’s type, and push it onto the stack.
The constant pool index is an unsigned value that immediately follows the opcode in the bytecode stream. Opcodes lcd1 and lcd2 push a 32-bit item onto the stack, such as an int or float. The difference between lcd1 and lcd2 is that lcd1 can only refer to constant pool locations one through 255 because its index is just 1 byte. (Constant pool location zero is unused.) lcd2 has a 2-byte index, so it can refer to any constant pool location. lcd2w also has a 2-byte index, and it is used to refer to any constant pool location containing a long or double, which occupy 64 bits. The opcodes that push constants from the constant pool are shown in the following table:

Pushing local variables onto the stack
Local variables are stored in a special section of the stack frame. The stack frame is the portion of the stack being used by the currently executing method. Each stack frame consists of three sections — the local variables, the execution environment, and the operand stack. Pushing a local variable onto the stack actually involves moving a value from the local variables section of the stack frame to the operand section. The operand section of the currently executing method is always the top of the stack, so pushing a value onto the operand section of the current stack frame is the same as pushing a value onto the top of the stack.
The Java stack is a last-in, first-out stack of 32-bit slots. Because each slot in the stack occupies 32 bits, all local variables occupy at least 32 bits. Local variables of type long and double, which are 64-bit quantities, occupy two slots on the stack. Local variables of type byte or short are stored as local variables of type int, but with a value that is valid for the smaller type. For example, an int local variable which represents a byte type will always contain a value valid for a byte (-128 <= value <= 127).
Each local variable of a method has a unique index. The local variable section of a method’s stack frame can be thought of as an array of 32-bit slots, each one addressable by the array index. Local variables of type long or double, which occupy two slots, are referred to by the lower of the two slot indexes. For example, a double that occupies slots two and three would be referred to by an index of two.
Several opcodes exist that push int and float local variables onto the operand stack. Some opcodes are defined that implicitly refer to a commonly used local variable position. For example, iload_0 loads the int local variable at position zero. Other local variables are pushed onto the stack by an opcode that takes the local variable index from the first byte following the opcode. The iload instruction is an example of this type of opcode. The first byte following iload is interpreted as an unsigned 8-bit index that refers to a local variable.
Unsigned 8-bit local variable indexes, such as the one that follows the iload instruction, limit the number of local variables in a method to 256. A separate instruction, called wide, can extend an 8-bit index by another 8 bits. This raises the local variable limit to 64 kilobytes. The wide opcode is followed by an 8-bit operand. The wide opcode and its operand can precede an instruction, such as iload, that takes an 8-bit unsigned local variable index. The JVM combines the 8-bit operand of the wide instruction with the 8-bit operand of the iload instruction to yield a 16-bit unsigned local variable index.
The opcodes that push int and float local variables onto the stack are shown in the following table:

The next table shows the instructions that push local variables of type long and double onto the stack. These instructions move 64 bits from the local variable section of the stack frame to the operand section.
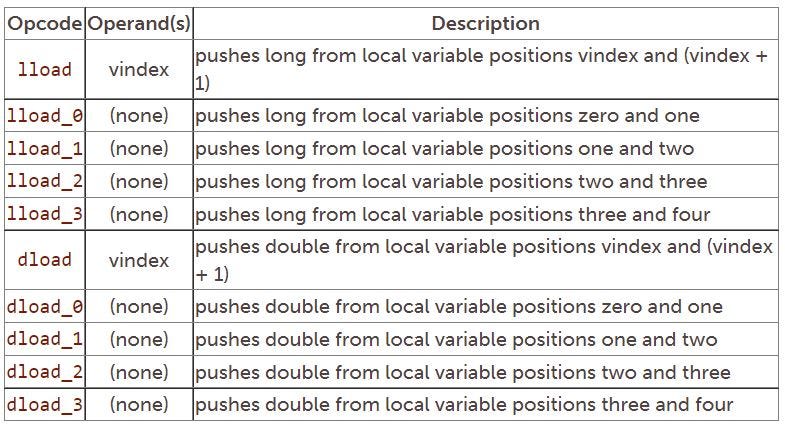
The final group of opcodes that push local variables move 32-bit object references from the local variables section of the stack frame to the operand section. These opcodes are shown in the following table:
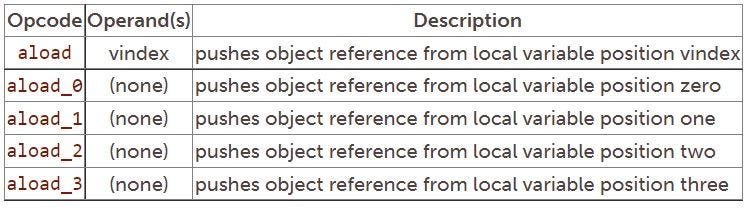
Popping to local variables
For each opcode that pushes a local variable onto the stack there exists a corresponding opcode that pops the top of the stack back into the local variable. The names of these opcodes can be formed by replacing “load” in the names of the push opcodes with “store”. The opcodes that pop ints and floats from the top of the operand stack to a local variable are listed in the following table. Each of these opcodes moves one 32-bit value from the top of the stack to a local variable.
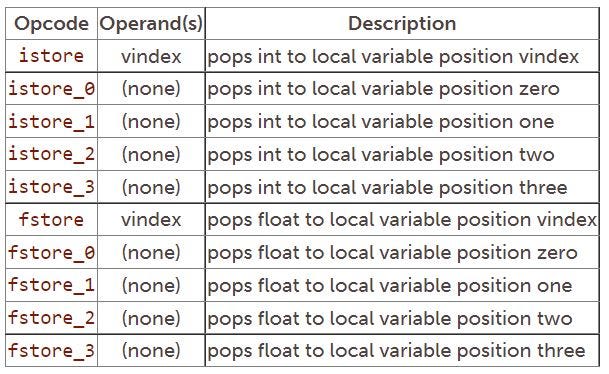
The next table shows the instructions that pop values of type long and double into a local variable. These instructions move a 64-bit value from the top of the operand stack to a local variable.

The final group of opcodes that pops to local variables are shown in the following table. These opcodes pop a 32-bit object reference from the top of the operand stack to a local variable.

Type conversions
The Java virtual machine has many opcodes that convert from one primitive type to another. No operands follow the conversion opcodes in the bytecode stream. The value to convert is taken from the top of the stack. The JVM pops the value at the top of the stack, converts it, and pushes the result back onto the stack. Opcodes that convert between int, long, float, and double are shown in the following table. There is an opcode for each possible from-to combination of these four types:

Opcodes that convert from an int to a type smaller than int are shown in the following table. No opcodes exist that convert directly from a long, float, or double to the types smaller than int. Therefore converting from a float to a byte, for example, would require two steps. First the float must be converted to an int with f2i, then the resulting int can be converted to a byte with int2byte.

Although opcodes exist that convert an int to primitive types smaller than int (byte, short, and char), no opcodes exist that convert in the opposite direction. This is because any bytes, shorts, or chars are effectively converted to int before being pushed onto the stack. Arithmetic operations upon bytes, shorts, and chars are done by first converting the values to int, performing the arithmetic operations on the ints, and being happy with an int result. This means that if you add 2 bytes you get an int, and if you want a byte result you must explicitly convert the int result back to a byte. For example, the following code won’t compile:
class BadArithmetic {
byte addOneAndOne() {
byte a = 1;
byte b = 1;
byte c = a + b;
return c;
}
}When presented with the above code, javac objects with the following remark:
BadArithmetic.java(7): Incompatible type for declaration. Explicit cast needed to convert int to byte.
byte c = a + b;
^To remedy the situation, the Java programmer must explicitly convert the int result of the addition of a + b back to a byte, as in the following code:
class GoodArithmetic {
byte addOneAndOne() {
byte a = 1;
byte b = 1;
byte c = (byte) (a + b);
return c;
}
}This makes javac so happy it drops a GoodArithmetic.class file, which contains the following bytecode sequence for the addOneAndOne() method:
iconst_1 // Push int constant 1.
istore_1 // Pop into local variable 1, which is a: byte a = 1;
iconst_1 // Push int constant 1 again.
istore_2 // Pop into local variable 2, which is b: byte b = 1;
iload_1 // Push a (a is already stored as an int in local variable 1).
iload_2 // Push b (b is already stored as an int in local variable 2).
iadd // Perform addition. Top of stack is now (a + b), an int.
int2byte // Convert int result to byte (result still occupies 32 bits).
istore_3 // Pop into local variable 3, which is byte c: byte c = (byte) (a + b);
iload_3 // Push the value of c so it can be returned.
ireturn // Proudly return the result of the addition: return c;Conversion diversion: a JVM simulation
The applet below demonstrates a JVM executing a sequence of bytecodes. The bytecode sequence in the simulation was generated by
javac
for the Convert() method of the class shown below:
class Diversion {
static void Convert() {
byte imByte = 0;
int imInt = 125;
while (true) {
++imInt;
imByte = (byte) imInt;
imInt *= -1;
imByte = (byte) imInt;
imInt *= -1;
}
}
}The actual bytecodes generated by javac for Convert() are shown below:
iconst_0 // Push int constant 0.
istore_0 // Pop to local variable 0, which is imByte: byte imByte = 0;
bipush 125 // Expand byte constant 125 to int and push.
istore_1 // Pop to local variable 1, which is imInt: int imInt = 125;
iinc 1 1 // Increment local variable 1 (imInt) by 1: ++imInt;
iload_1 // Push local variable 1 (imInt).
int2byte // Truncate and sign extend top of stack so it has valid byte value.
istore_0 // Pop to local variable 0 (imByte): imByte = (byte) imInt;
iload_1 // Push local variable 1 (imInt) again.
iconst_m1 // Push integer -1.
imul // Pop top two ints, multiply, push result.
istore_1 // Pop result of multiply to local variable 1 (imInt): imInt *= -1;
iload_1 // Push local variable 1 (imInt).
int2byte // Truncate and sign extend top of stack so it has valid byte value.
istore_0 // Pop to local variable 0 (imByte): imByte = (byte) imInt;
iload_1 // Push local variable 1 (imInt) again.
iconst_m1 // Push integer -1.
imul // Pop top two ints, multiply, push result.
istore_1 // Pop result of multiply to local variable 1 (imInt): imInt *= -1;
goto 5 // Jump back to the iinc instruction: while (true) {}The Convert() method demonstrates the manner in which the JVM converts from int to byte. imInt starts out as 125. Each pass through the while loop, it is incremented and converted to a byte. Then it is multiplied by -1 and again converted to a byte. The simulation quickly shows what happens at the edges of the valid range for the byte type.
The maximum value for a byte is 127. The minimum value is -128. Values of type int that are within this range convert directly to byte. However, as soon as the int gets beyond the valid range for byte, things get interesting.
The JVM converts an int to a byte by truncating and sign extending. The highest order bit, the “sign bit,” of longs, ints, shorts, and bytes indicate whether or not the integer value is positive or negative. If the sign bit is zero, the value is positive. If the sign bit is one, the value is negative. Bit 7 of a byte value is its sign bit. To convert an int to a byte, bit 7 of the int is copied to bits 8 through 31. This produces an int that has the same numerical value that the int’s lowest order byte would have if it were interpreted as a byte type. After the truncation and sign extension, the int will contain a valid byte value.
The simulation applet shows what happens when an int that is just beyond the valid range for byte types gets converted to a byte. For example, when the imInt variable has a value of 128 (0x00000080) and is converted to byte, the resulting byte value is -128 (0xffffff80). Later, when the imInt variable has a value of -129 (0xffffff7f) and is converted to byte, the resulting byte value is 127 (0x0000007f).
How the Java virtual machine handles exceptions.
A detailed study with examples of classes and methods.
Welcome to another installment of Under The Hood. This column aims to give Java developers a glimpse of the mysterious mechanisms clicking and whirring beneath their running Java programs. This month’s article continues the discussion of the bytecode instruction set of the Java virtual machine by examining the manner in which the Java virtual machine handles exception throwing and catching, including the relevant bytecodes. This article does not discuss finally clauses -- that's next month's topic. Subsequent articles will discuss other members of the bytecode family.
Exceptions
Exceptions allow you to smoothly handle unexpected conditions that occur as your programs run. To demonstrate the way the Java virtual machine handles exceptions, consider a class named
NitPickyMath
that provides methods that perform addition, subtraction, multiplication, division, and remainder on integers.
NitPickyMath
performs these mathematical operations the same as the normal operations offered by Java’s “+”, “-”, “*”, “/”, and “%” operators, except the methods in
NitPickyMath
throw checked exceptions on overflow, underflow, and divide-by-zero conditions. The Java virtual machine will throw an
ArithmeticException
on an integer divide-by-zero, but will not throw any exceptions on overflow and underflow. The exceptions thrown by the methods of
NitPickyMath
are defined as follows:
class OverflowException extends Exception {
}
class UnderflowException extends Exception {
}
class DivideByZeroException extends Exception {
}A simple method that catches and throws exceptions is the remainder method of class NitPickyMath:
static int remainder(int dividend, int divisor)
throws DivideByZeroException {
try {
return dividend % divisor;
}
catch (ArithmeticException e) {
throw new DivideByZeroException();
}
}The remainder method simply performs the remainder operation upon the two ints passed as arguments. The remainder operation throws an ArithmeticException if the divisor of the remainder operation is a zero. This method catches this ArithmeticException and throws a DivideByZeroException.
The difference between a DivideByZero and an ArithmeticException exception is that the DivideByZeroException is a checked exception and the ArithmeticException is unchecked. Because the ArithmeticException is unchecked, a method need not declare this exception in a throws clause even though it might throw it. Any exceptions that are subclasses of either Error or RuntimeException are unchecked. (ArithmeticException is a subclass of RuntimeException.) By catching ArithmeticException and then throwing DivideByZeroException, the remainder method forces its clients to deal with the possibility of a divide-by-zero exception, either by catching it or declaring DivideByZeroException in their own throws clauses. This is because checked exceptions, such as DivideByZeroException, thrown within a method must be either caught by the method or declared in the method's throws clause. Unchecked exceptions, such as ArithmeticException, need not be caught or declared in the throws clause.
javac generates the following bytecode sequence for the remainder method:
The main bytecode sequence for remainder:
0 iload_0 // Push local variable 0 (arg passed as divisor)
1 iload_1 // Push local variable 1 (arg passed as dividend)
2 irem // Pop divisor, pop dividend, push remainder
3 ireturn // Return int on top of stack (the remainder)
The bytecode sequence for the catch (ArithmeticException) clause:
4 pop // Pop the reference to the ArithmeticException
// because it isn't used by this catch clause.
5 new #5 <Class DivideByZeroException>
// Create and push reference to new object of class
// DivideByZeroException.
DivideByZeroException
8 dup // Duplicate the reference to the new
// object on the top of the stack because it
// must be both initialized
// and thrown. The initialization will consume
// the copy of the reference created by the dup.
9 invokenonvirtual #9 <Method DivideByZeroException.<init>()V>
// Call the constructor for the DivideByZeroException
// to initialize it. This instruction
// will pop the top reference to the object.
12 athrow // Pop the reference to a Throwable object, in this
// case the DivideByZeroException,
// and throw the exception.The bytecode sequence of the remainder method has two separate parts. The first part is the normal path of execution for the method. This part goes from pc offset zero through three. The second part is the catch clause, which goes from pc offset four through twelve.
The irem instruction in the main bytecode sequence may throw an ArithmeticException. If this occurs, the Java virtual machine knows to jump to the bytecode sequence that implements the catch clause by looking up and finding the exception in a table. Each method that catches exceptions is associated with an exception table that is delivered in the class file along with the bytecode sequence of the method. The exception table has one entry for each exception that is caught by each try block. Each entry has four pieces of information: the start and end points, the pc offset within the bytecode sequence to jump to, and a constant pool index of the exception class that is being caught. The exception table for the remainder method of class NitPickyMath is shown below:
Exception table:
from to target type
0 4 4 <Class java.lang.ArithmeticException>The above exception table indicates that from pc offset zero through three, inclusive, ArithmeticException is caught. The try block's endpoint value, listed in the table under the label "to", is always one more than the last pc offset for which the exception is caught. In this case the endpoint value is listed as four, but the last pc offset for which the exception is caught is three. This range, zero to three inclusive, corresponds to the bytecode sequence that implements the code inside the try block of remainder. The target listed in the table is the pc offset to jump to if an ArithmeticException is thrown between the pc offsets zero and three, inclusive.
If an exception is thrown during the execution of a method, the Java virtual machine searches through the exception table for a matching entry. An exception table entry matches if the current program counter is within the range specified by the entry, and if the exception class thrown is the exception class specified by the entry (or is a subclass of the specified exception class). The Java virtual machine searches through the exception table in the order in which the entries appear in the table. When the first match is found, the Java Virtual Machine sets the program counter to the new pc offset location and continues execution there. If no match is found, the Java virtual machine pops the current stack frame and rethrows the same exception. When the Java virtual machine pops the current stack frame, it effectively aborts execution of the current method and returns to the method that called this method. But instead of continuing execution normally in the previous method, it throws the same exception in that method, which causes the Java virtual machine to go through the same process of searching through the exception table of that method.
A Java programmer can throw an exception with a throw statement such as the one in the catch (ArithmeticException) clause of remainder, where a DivideByZeroException is created and thrown. The bytecode that does the throwing is shown in the following table:

The athrow instruction pops the top word from the stack and expects it to be a reference to an object that is a subclass of Throwable (or Throwable itself). The exception thrown is of the type defined by the popped object reference.
Play Ball!: a Java virtual machine simulation
The applet below demonstrates a Java virtual machine executing a sequence of bytecodes. The bytecode sequence in the simulation was generated by
javac
for the
playBall
method of the class shown below:
class Ball extends Exception {
}
class Pitcher {
private static Ball ball = new Ball();
static void playBall() {
int i = 0;
while (true) {
try {
if (i % 4 == 3) {
throw ball;
}
++i;
}
catch (Ball b) {
i = 0;
}
}
}
}The bytecodes generated by javac for the playBall method are shown below:
0 iconst_0 // Push constant 0
1 istore_0 // Pop into local var 0: int i = 0;
// The try block starts here (see exception table, below).
2 iload_0 // Push local var 0
3 iconst_4 // Push constant 4
4 irem // Calc remainder of top two operands
5 iconst_3 // Push constant 3
6 if_icmpne 13 // Jump if remainder not equal to 3: if (i % 4 == 3) {
// Push the static field at constant pool location #5,
// which is the Ball exception itching to be thrown
9 getstatic #5 <Field Pitcher.ball LBall;>
12 athrow // Heave it home: throw ball;
13 iinc 0 1 // Increment the int at local var 0 by 1: ++i;
// The try block ends here (see exception table, below).
16 goto 2 // jump always back to 2: while (true) {}
// The following bytecodes implement the catch clause:
19 pop // Pop the exception reference because it is unused
20 iconst_0 // Push constant 0
21 istore_0 // Pop into local var 0: i = 0;
22 goto 2 // Jump always back to 2: while (true) {}
Exception table:
from to target type
2 16 19 <Class Ball>The playball method loops forever. Every fourth pass through the loop, playball throws a Ball and catches it, just because it is fun. Because the try block and the catch clause are both within the endless while loop, the fun never stops. The local variable i starts at 0 and increments each pass through the loop. When the if statement is true, which happens every time i is equal to 3, the Ball exception is thrown.
The Java virtual machine checks the exception table and discovers that there is indeed an applicable entry. The entry’s valid range is from 2 to 15, inclusive, and the exception is thrown at pc offset 12. The exception caught by the entry is of class Ball, and the exception thrown is of class Ball. Given this perfect match, the Java virtual machine pushes the thrown exception object onto the stack, and continues execution at pc offset 19. The catch clause merely resets int i to 0, and the loop starts over.
Reference :- Krishantha Dinesh , https://www.javatpoint.com/jvm-java-virtual-machine# , Bill Venners , Rafael Del Niro , Matthew Tyson.
E-Mail :- gawesh2020java@gmail.com
Blog :- https://gaweshprabhashwara.blogspot.com/
Youtube :- https://www.youtube.com/channel/UCwm7djDtBaueTDqXt_GIFKw
Linkedin :- https://lk.linkedin.com/in/gawesh-prabhashwara-792ab1205
Facebook :- https://www.facebook.com/gawesh98
Twitter :- https://twitter.com/gawesh_98
Instagram :- https://www.instagram.com/gawezh/
Tiktok :- https://www.tiktok.com/@gawesh_prabhashwara?lang=en











0 Comments