
Kafka or RabbitMQ.

What is Kafka?
Apache Kafka is a distributed event store and stream-processing platform. It is an open-source system developed by the Apache Software Foundation written in Java and Scala. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Kafka can connect to external systems (for data import/export) via Kafka Connect, and provides the Kafka Streams libraries for stream processing applications. Kafka uses a binary TCP-based protocol that is optimized for efficiency and relies on a “message set” abstraction that naturally groups messages together to reduce the overhead of the network roundtrip. This “leads to larger network packets, larger sequential disk operations, contiguous memory blocks […] which allows Kafka to turn a bursty stream of random message writes into linear writes.”
RabbitMQ is an open-source message-broker software (sometimes called message-oriented middleware) that originally implemented the Advanced Message Queuing Protocol (AMQP) and has since been extended with a plug-in architecture to support Streaming Text Oriented Messaging Protocol (STOMP), MQ Telemetry Transport (MQTT), and other protocols.[1]
Written in Erlang, the RabbitMQ server is built on the Open Telecom Platform framework for clustering and failover. Client libraries to interface with the broker are available for all major programming languages. The source code is released under the Mozilla Public License.
Why we need a Messaging System?
Data is transferred between apps through a messaging system, freeing the programs to concentrate on the data themselves without being distracted by the exchange and transmission of data. Reliable message queuing serves as the foundation for distributed messaging. Client applications and the messaging system queue messages in an asynchronous fashion.The majority of the time, we use REST-based microservices in our implementations. When we implement a REST-based solution, the design or standard states that it is asynchronous. Asynchronous indicates that we do not wait for the next event to occur. The HTTP protocol, which is synchronous, is the one we utilize for microservices the majority of the time. As long as we continue to use REST over HTTP while constructing microservices, this becomes synchronous. So, the messaging is your biggest and greatest option to prevent that.
What is Synchronous?
Synchronous Transmission: In Synchronous Transmission, data is sent in form of blocks or frames. This transmission is the full-duplex type. Between sender and receiver, synchronization is compulsory. In Synchronous transmission, There is no gap present between data. It is more efficient and more reliable than asynchronous transmission to transfer a large amount of data.

What is Asynchronous?
Asynchronous Transmission: In Asynchronous Transmission, data is sent in form of byte or character. This transmission is the half-duplex type transmission. In this transmission start bits and stop bits are added with data. It does not require synchronization.

RabbitMQ and Kafka Performance.
Apache Kafka:
Kafka offers much higher performance than message brokers like RabbitMQ. It uses sequential disk I/O to boost performance, making it a suitable option for implementing queues. It can achieve high throughput (millions of messages per second) with limited resources, a necessity for big data use cases.
RabbitMQ:
RabbitMQ can also process a million messages per second but requires more resources (around 30 nodes). You can use RabbitMQ for many of the same use cases as Kafka, but you’ll need to combine it with other tools like Apache Cassandra.
Kafka Architecture.

Producers and consumers are the same here — applications that publish and read event messages, respectively. As we’ve covered when we discussed Kafka use cases, an event is a message with data describing the event, such as a new user signing up to a mobile application. Events are queued in Kafka topics, and multiple consumers can subscribe to the same topic. Topic are further divided into partitions, which split data across brokers to improve performance.
Important features of Kafka include:
- High volume publish-subscribe messages and streams platform — durable, fast, and scalable.
- Durable message store — Kafka behaves like a log, run in a server cluster, which keeps streams of records in topics (categories).
- Messages are made up of a value, a key, and a timestamp.
- Dumb broker / smart consumer model — does not try to track which messages are read by consumers and only keeps unread messages. Kafka keeps all messages for a set period of time.
- Managed by external services — in many cases this will be Apache Zookeeper.
RabbitMQ Architecture.

As with other message brokers, RabbitMQ receives messages from applications that publish them — known as producers or publishers. Within the system, messages are received at an exchanges — a virtual ‘post-office’ of sorts, which routes messages onwards to storage buffers known as queues. Applications that read messages, known as consumers, can subscribe to these queues to pick up the latest data that arrives in the ‘mailboxes’.
The key features of RabbitMQ are:
- General purpose message broker — uses variations of request/reply, point to point, and pub-sub communication patterns.
- Smart broker / dumb consumer model — consistent delivery of messages to consumers, at around the same speed as the broker monitors the consumer state.
- Mature platform — well supported, available for Java, client libraries, .NET, Ruby, node.js. Offers dozens of plugins.
- Communication — can be synchronous or asynchronous.
- Deployment scenarios — provides distributed deployment scenarios.
- Multi-node cluster to cluster federation — does not rely on external services, however, specific cluster formation plugins can use DNS, APIs, Consul, etc.
Pull vs Push Approach.
One important difference between Kafka and RabbitMQ is that the first is pull-based, while the other is push-based. In pull-based systems, the brokers waits for the consumer to ask for data (‘pull’); if a consumer is late, it can catch up later. With push-based systems, messages are immediately pushed to any subscribed consumer. This can cause these two tools to behave differently in some circumstances.
Apache Kafka: Pull-based approach.
Kafka uses a pull model. Consumers request batches of messages from a specific offset. Kafka permits long-pooling, which prevents tight loops when there is no message past the offset, and aggressively batches messages to support this
A pull model is logical for Kafka because of partitioned data structure. Kafka provides message order in a partition with no contending consumers. This allows users to leverage the batching of messages for effective message delivery and higher throughput.
RabbitMQ: Push-based approach.
RabbitMQ uses a push model and stops overwhelming consumers through a prefetch limit defined on the consumer. This can be used for low latency messaging..
The aim of the push model is to distribute messages individually and quickly, to ensure that work is parallelized evenly and that messages are processed approximately in the order in which they arrived in the queue. However, this can also cause issues in cases where one or more consumers have ‘died’ and are no longer receiving messages.
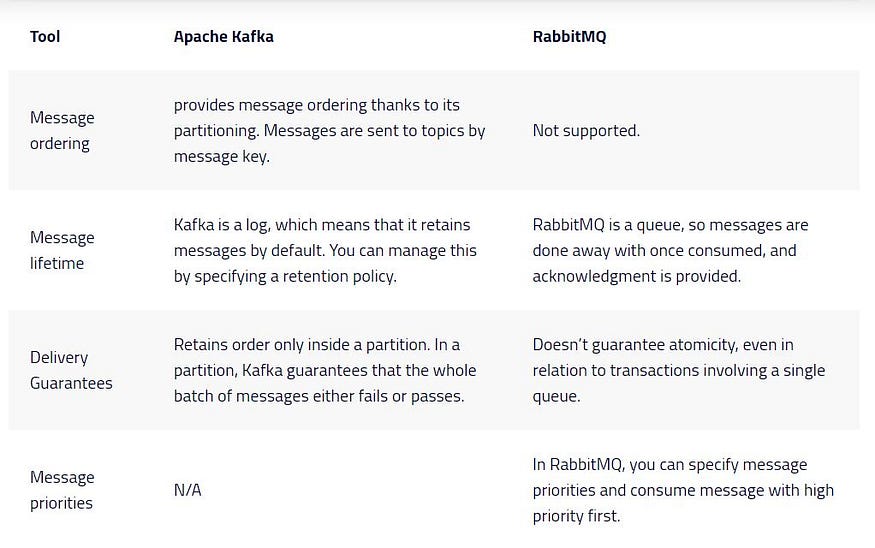
How Do They Handle Messaging?
Kafka Use Cases.
Some of the best Kafka use cases make use of the platform’s high throughput and stream processing capabilities.
High-throughput activity tracking: Kafka can be used for a variety of high-volume, high-throughput activity-tracking applications. For example, you can use Kafka to track website activity (its original use case), ingest data from IoT sensors, monitor patients in hospital settings, or keep tabs on shipments.
Stream processing: Kafka enables you to implement application logic based on streams of events. You might keep a running count of types of events or calculate an average value over the course of an event that lasts several minutes. For example, if you have an IoT application that incorporates automated thermometers, you could keep track of the average temperature over time and trigger alerts if readings deviate from a target temperature range.
Event sourcing: Kafka can be used to support event sourcing, in which changes to an app state are stored as a sequence of events. So, for example, you might use Kafka with a banking app. If the account balance is somehow corrupted, you can recalculate the balance based on the stored history of transactions.
Log aggregation: Similar to event sourcing, you can use Kafka to collect log files and store them in a centralized place. These stored log files can then provide a single source of truth for your app.
RabbitMQ Use Cases.
Some of the best RabbitMQ use cases make use of its flexibility — both for routing messages within microservices architectures and among legacy apps.
Complex routing: RabbitMQ can be the best fit when you need to route messages among multiple consuming apps, such as in a microservices architecture. RabbitMQ consistent hash exchange can be used to balance load processing across a distributed monitoring service, for example. Alternate exchanges can also be used to route a portion of events to specific services for A/B testing.
Legacy applications: Using available plug-ins (or developing your own), you can deploy RabbitMQ as a way to connect consumer apps with legacy apps. For example, you can use a Java Message Service (JMS) plug-in and JMS client library to communicate with JMS apps.
Reference :-
Krishantha Dinesh, Eran Levy, Wikipedia.
Author :- Gawesh Prabhashwara.
E-Mail :- gawesh2020java@gmail.com
Blog :- https://gaweshprabhashwara.blogspot.com/
Youtube :- https://www.youtube.com/channel/UCwm7djDtBaueTDqXt_GIFKw
Linkedin :- https://lk.linkedin.com/in/gawesh-prabhashwara-792ab1205
Facebook :- https://www.facebook.com/gawesh98
Twitter :- https://twitter.com/gawesh_98
Instagram :- https://www.instagram.com/gawezh/
Tiktok :- https://www.tiktok.com/@gawesh_prabhashwara?lang=en











0 Comments